Project description
Time in Translation: the semantics of the Perfect
1. Problem statement and scientific relevance
In the 1960s the first modern language corpus boasted one million words. Every subdiscipline of linguistics has since compiled its own corpora with ranges that sometimes go into billions. By now, usage-driven approaches to language are changing the fields of linguistics. One example is the field of typology where quantitative corpus methods have started to claim their rightful place (e.g. Wälchli & Cysouw 2012). But it still proves hard to bring together the interests of computationally oriented linguists with those of more theoretically oriented ones. We argue that progress can be made by applying quantitative corpus methods in the field of micro-typology. Micro-typology is the area of linguistics that considers closely related languages/dialects as a laboratory for linguistic theory by fine-tuning our understanding of the meaning and form of words/sentences/discourse (de Swart 2007, Barbiers 2014). Our focus will be on meaning and in particular on that of the Perfect, a tense marked in English by the auxiliary HAVE followed by a past participle (e.g. ‘has sung’).
2. Overall aim and delimitation
What is the semantics of the Perfect? Despite its provocatively simple formulation, our main research question is a real challenge for linguistic theory (Ritz 2012). This is due to the fact that the Perfect is a synchronically and diachronically unstable category (Lindstedt 2000) as it is in constant competition with the rest of the tense-aspect categories of a given language (Schaden 2009). Our aim is to capture this competition and uncover the semantics of the Perfect by providing the first semantic micro-typological analysis of the Perfect. Crucially, such a micro-typology should extend the current focus of language-specific analyses (see Kamp & Rossdeutscher 2013 and references therein) from sentence-internal combinatorics to discourse (de Swart 2007). Figure 1 schematically shows how languages provide different pieces of the Perfect puzzle under a competition view.
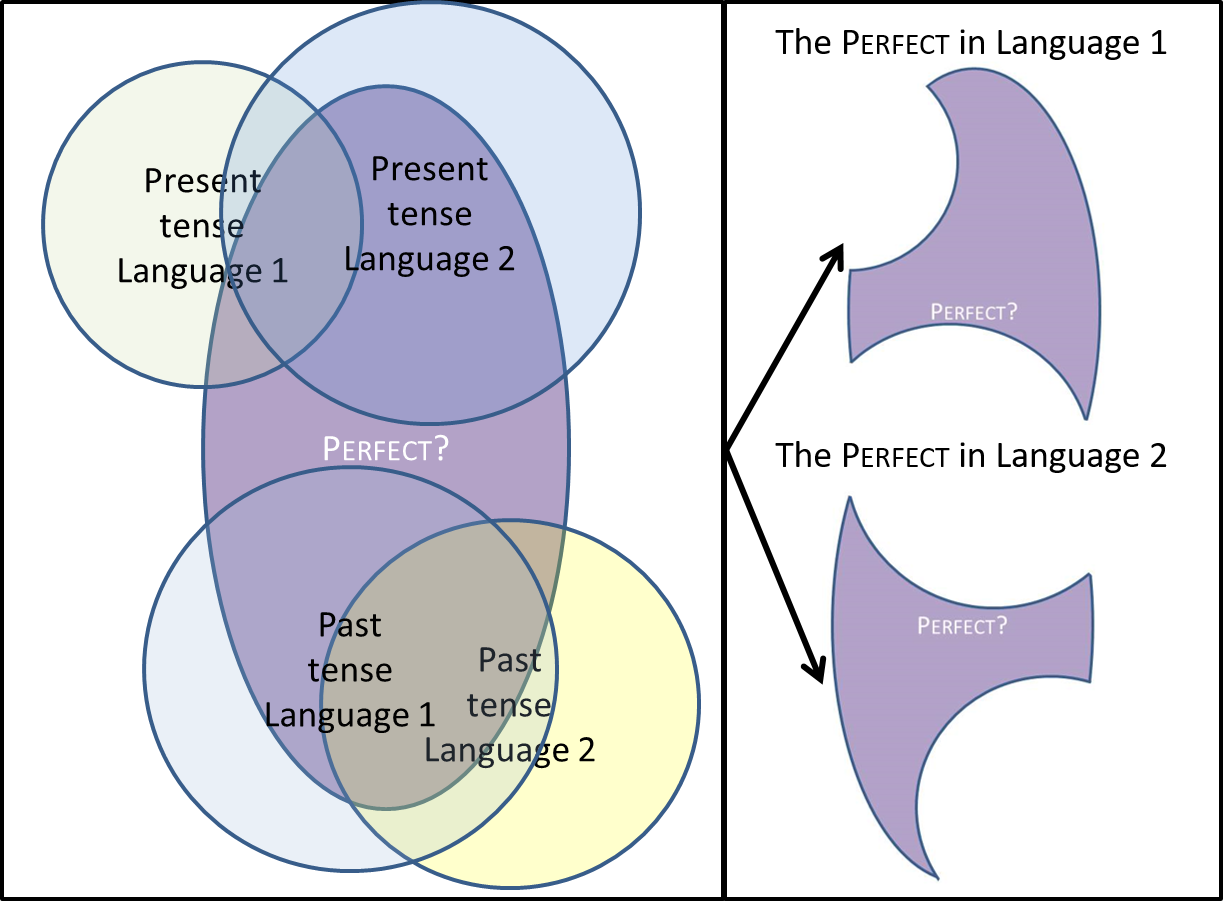
Figure 1
We zoom in on the manifestation of the Perfect that Dahl & Velupillai (2013) trace back to a transitive possessive construction, the Have Perfect (Figure 2). The Have Perfect manifests itself in languages like English, Dutch, German, French and Spanish. The tense-aspect systems of these languages are closely related, yet fundamentally different (presence/absence of progressive/non-progressive, perfective/ imperfective, competing perfective past tense), thus guaranteeing sufficient room for variation. Unlike syntactic work on micro-typology, we focus on the language- rather than the dialect-level. This difference in granularity guarantees the semantic traceability of variation (Koeneman et al. 2011) but doesn’t mean we are unaware of the necessity to control for dialectal differences (Ritz & Engel 2008).
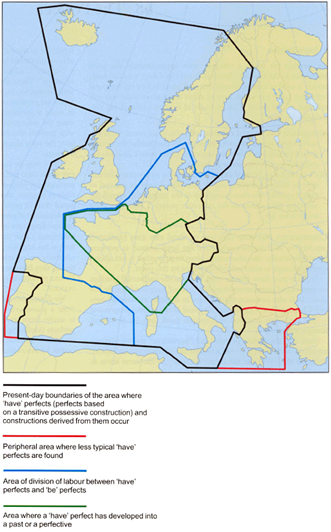
Figure 2 (Dahl & Velupillai 2013)
3. Approach and innovation
3.1. Why classical methodologies won’t do
3.1. Why classical methodologies won’t do
Formal semantic approaches to the Perfect (e.g. Portner 2002) are driven by sets of predefined usages exemplified by prototypical instantiations. Linguists commonly distinguish between three core perfect meanings:
(1) a. Mary has visited Paris. (her past visit to Paris is relevant now) [experiential]
b. Mary has moved to Paris. (she currently lives in Paris) [resultative]
c. Mary has lived in Paris for five years (now) (she moved there five years ago). [continuative]
Taking these as a starting point for cross-linguistic investigation leads to a skewed view on variation and on the Perfect itself. This is what pilots of the improved strategy we introduce in 3.2. show us. Examples (1) and (2) are adapted for space reasons.
French is known to select the Present rather than the Perfect in contexts like (1c):
(2) [Mary has moved to Paris 5 years ago and continues to live there]
Marie habite/ ?a habité à Paris depuis 5 ans. [continuation in French]
Marie lives/?has lived in Paris since 5 years
This has led theoretical semanticists to claim that the French Passé Composé lacks the continuative Perfect reading (e.g. Nishiyama & König 2010). However, as soon as the context is slightly different, a continuative reading emerges (corpus example):
(2’) C’est ce qu’a fait l’humanité depuis le début. [continuative perfect, French]
‘That’s what humanity has been doing from the start’.
The contrast between (2) and (2’) shows that we need to move from constructing data that fit our predefined usages to usages that fit the data.
The classical way to discover new usages is to classify data for each language and check whether the predefined usages suffice. For the Perfect this methodology would be insufficient, as it would miss out on the discourse dimension of the Perfect. Rather than merely expressing run-of-the-mill resultant states, the Perfects in (3) and (4) play a special role at the level of discourse interaction. To see this, note that these Perfects can replace the PASTs in the monologues in (5) and (6) but not vice versa.
(3) A: Hoe ging het? A: How did it go?
B: Het is gelukt! B: It has succeeded! (≈ we managed!)
(4) A: Jongens, kom gauw kijken! Ik heb een babypanda gevonden!
B: Wauw, wat een schatje!
A: Guys, quickly, come look! I have found a baby panda!
B: Wow, what a cutie!
(5) Ik probeerde op het dak te komen. Uiteindelijk lukte het.
I tried to get on the roof. In the end, it succeeded (≈ I managed)
(6) In de jungle vond ik een babypanda. Wat een vondst!
In the jungle, I found a baby panda. What a finding!
Even within dialogue, we find two discourse uses: the Perfect in (3B) provides a complete answer to the challenge introduced by A, whereas (4B) introduces a new topic (the baby panda) for follow-up interaction by B. So the Perfect is backward-looking in (3) and forward-looking in (4). The two directions each occur in their own discourse configuration: backward uses are found to close off an issue, while forward looking uses are found when a new issue is placed on the table. This suggests that Perfects are essentially non-narrative, and are used at the ‘edges’ of discourse sequences (beginning/end), where they link from or to the utterance situation. This discourse use is found across languages, but is not necessarily restricted to the Perfect. Note that English allows its Past in contexts like (3) and (4) (‘We managed!’ ‘We found a baby panda!’), unlike Dutch (van der Klis, Le Bruyn & de Swart 2015). Existing discourse theories have mainly focused on anaphoric tense use, but the examples in (3) and (4) suggest that cross-linguistic variation might be particularly relevant in non-narrative contexts. Our discourse investigations will thus have to place special emphasis on the beginning and end of discourse sequences, and should not only be concerned with narrative discourse, but include other genres (informative texts, dialogue) as well.
3.2. Our approach
Step 1: Translation Mining
If variation in form reflects variation in usage, one can use translations to discover different usages of a single form. For example, the Dutch verb lenen is translated into French in two ways (prêter|emprunter), suggesting that it has two different usages (receiving|giving). This principle underlies the literature on semantic maps, spatial layouts that represent how usages are related to one another and how specific lexical items/grammatical forms map onto these as in Figure 3.
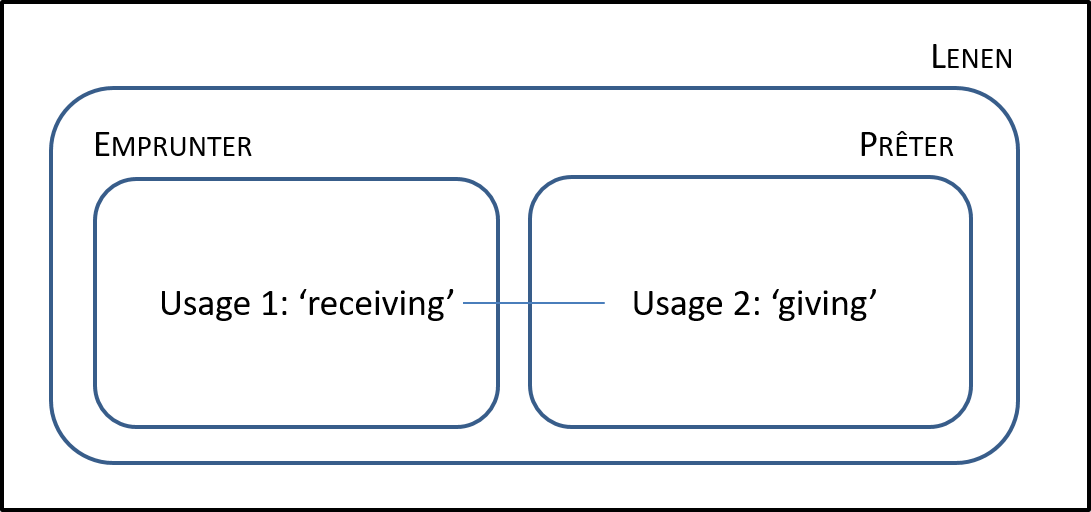
Figure 3
Dahl (2015) convincingly shows that variation in the Perfect domain can be tackled through inductive corpus methods. However, he is after the identification of prototypical Perfects and falls short of providing the data needed to construct a full semantics of the Perfect. We adopt a different method that we dub Translation Mining. It exploits the basic insight of semantic map methodology and was originally designed by Wälchli & Cysouw (2012) to inductively build semantic maps of lexical items. Wälchli & Cysouw select contexts in actual texts and track whether languages differ in the lexical items they use in each of these contexts. Figure 4 shows how Dutch uses the same verb in Contexts 1-4 whereas French uses emprunter in 1/4 and prêter in 2/3. This means 1/4 pattern together and 2/3 as well. These clusters make up inductively defined usages. To scale up Translation Mining Wälchli & Cysouw resort to statistical techniques (Distance Matrices) and a visualization tool (Multidimensional Scaling).
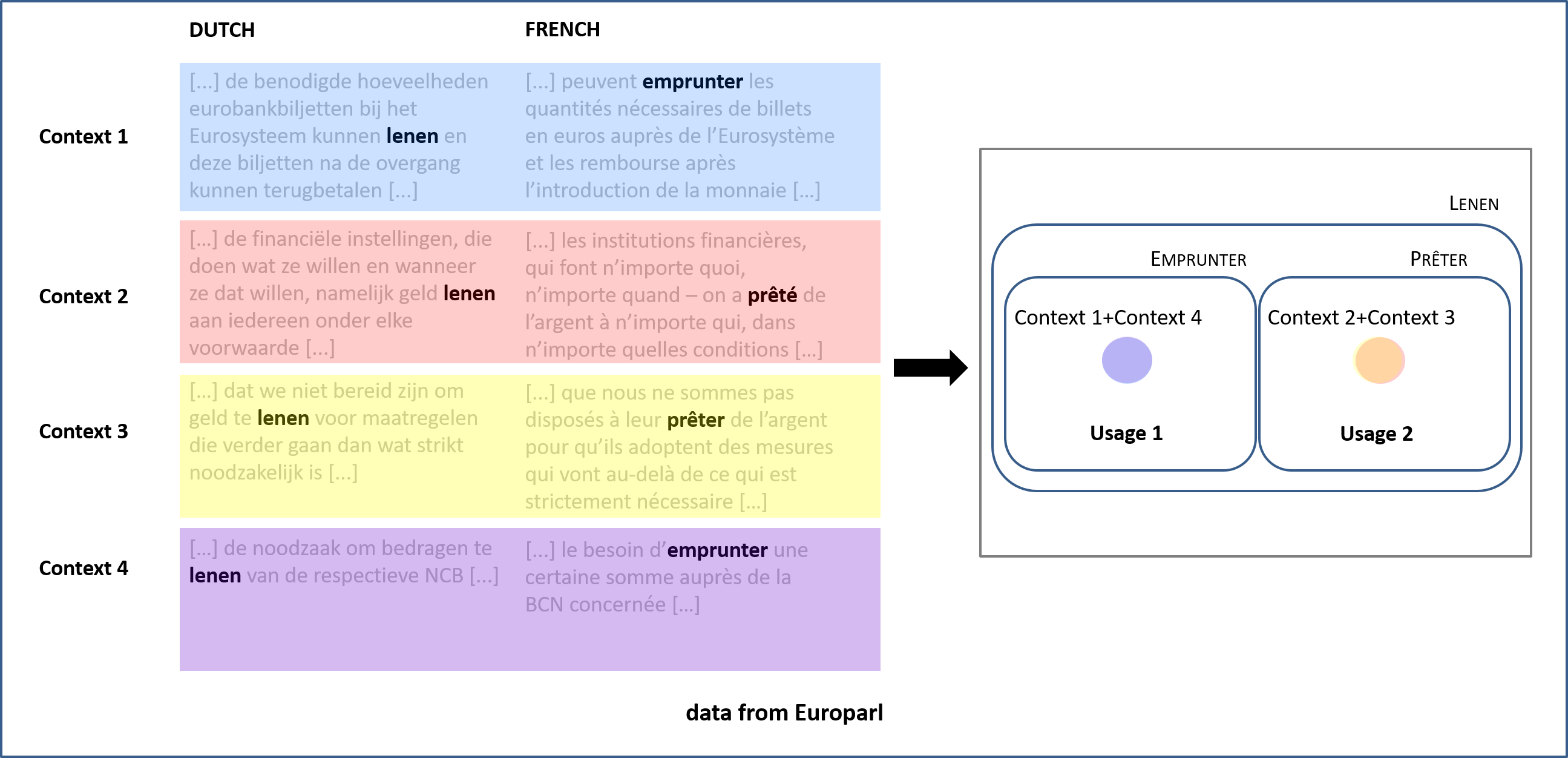
Figure 4
Our novel insight is that Translation Mining cannot only be applied in lexical but also in grammatical research, if grammatical theory can link variation at word level (the unit of analysis of Translation Mining) to variation in the language system. This is the case for our competition-driven approach to the Perfect: we exploit variation in tense usage to inform us about the semantics of the Perfect at the sentence and the discourse level.
We apply Translation Mining to 5.000 contexts in which at least one of the languages of our sample uses a Perfect. This corresponds to a total of 25.000 individual language data points. By dividing these contexts over corpora representing formal dialogues (Europarl), informal dialogues (Opensubtitles.org) and informative texts (Digital Corpus of the European Parliament) we also track genre variation. This gives us a head start in teasing apart sentence-level usages (constant over the three corpora) and discourse-interaction usages in dialogue (absent from DCEP). The numbers we propose here are based on our newest pilot findings and strike a balance between big data (needed to cover all usages) and data that are manageable for the part of Translation Mining that we perform manually (identification of translations) and for further analysis.
The number of languages in our database will gradually be increased (potentially for a subset of our data) in collaboration with BA and MA students working on tense/aspect for their internship/thesis. This will lead to an ever more fine-grained view on the data. We count on adding at least two further Romance and two further Germanic languages.
Step 2: The theoretical turn
Obviously, inductively induced data clusters don’t wear their semantics on their sleeve. So the outcome of Translation Mining is a uniquely structured data set, but one that is still in need of interpretation. It however holds the key to questions about the Perfect that the literature has never been able to address before:- Are the sentence-level usages from the literature covering all actual usages?
- How can we model and make sense of the discourse-interaction usages?
- How do the usages hang together or – put differently – is it feasible to relate all usages to one underlying semantics?
Our pilots already show that current overviews of sentence-level usages don’t suffice (cf. (1) vs. (2), (2’)), but we need a larger dataset to get a full overview. As most classical discourse models (e.g. Partee 1984) do not cover forward-looking tense uses, the discourse dimension of the Perfect requires us to build tense/aspect extensions of models like Inquisitive Semantics (Ciardelli et al. 2013). Finally, relating usage to grammar requires the construction of an independently motivated semantics of the (Have) Perfect that makes falsifiable predictions about possible usages. This semantics will be an extension of the one Le Bruyn et al. (2016) propose for relational Have, a verb that is semantically characterized by its capacity to invert relations. For sentence uses HAVE combines with a passive state denoting past participle and turns it into an active one, allowing its subject to function as the agent of the event underlying the state. For discourse interaction, we know relations between discourse moves can be backward- and forward-looking. Inverting these relations has no consequences for the spectrum of possibilities, allowing the Perfect – unlike the Past – to be backward- ànd forward-looking (examples (3)/(4)).
Step 3: Putting the theory to the test
The outcome of our analysis is a fine-grained theory of the Have Perfect inductively obtained on the basis of translation data. To complete the argumentative cycle we use (i) a further 3000 contexts from the translation corpora, add the annotations our analyses require and check whether our theory correctly predicts the variation we find, (ii) crowdsourcing-based experiments to link our translation-based theory to the actual grammars of the individual languages.In sum, Step 1 constitutes a long-overdue empirical turn in the study of the Perfect. We innovate Translation Mining by exploiting it not for lexical meaning, but for grammar, and by tracking genre variation. Step 2 is theoretically groundbreaking as we will be the first to build a tense/aspect semantics that integrates sentence and discourse-interaction usages. Step 3 is the icing on the cake as it moves the project from description and theory to prediction, a unique move in data-driven approaches.
4. Knowledge utilization
Education: (Secondary) school methods for language teaching all introduce the tense-aspect system of the language, and provide prototypical examples for their use. However, the appropriate use of past, present and perfect forms in context raises important challenges for second language learners, because of the subtleties in sentence-level and discourse-level meanings. Creating inquiry-based learning modules for language classes is one of the challenges high school teachers are increasingly confronted with (e.g. Schnabel et al. 2015, Neijt et al. 2016). With students from the Educational Masters we exploit our data sets to develop these for the languages of our project, covering all classical school languages. The course modules will be made available through our website and advertised through presentations at the Landelijke LIO-dag and the Landelijke Studiedag van Levende Talen.
Translation: Because tense-aspect distinctions are quite different across languages, translators often struggle to convey temporal reference in the target language. Current insights in contrastive linguistics are insufficient, because they focus on grammar, rather than discourse. The stakes are high, because translators have no choice but to deal with this variation. We anticipate two relevant products of our research for translators:
- We will develop an online course module on Time in Translation, which is set up to make insights from cross-linguistic semantic research on the Perfect accessible to translation students and professional translators. We will test the module in pre-master courses, translation workshops in the context of the Masterlanguage programme, and alumni meetings for language students.
- With the help of AI students and the Utrecht Digital Humanities Lab, we will develop software to generate translation predictions to check the adequacy of our theory of the Perfect. In this way, we work the results of our research into a translation software plugin (MIT license) for professional translators.
Computational linguistics: Publications within computational linguistics that have been of significant inspiration to us include Grisot & Meyer (2014), Loáiciga et al. (2014), Zarcone & Lenci (2008), Im & Pustejovsky (2010). Our project will incorporate but also go beyond their insights. We aim to enhance machine translation by offering a more in-depth analysis of how tense/aspect interacts with sentence/discourse and different text types, developing – where possible – new ways of annotating natural language data. We further aim to extend and improve on existing tense/aspect annotation systems. Independently of our own contributions, we will make all our (annotated) data available for the larger research community.
Selected references
Barbiers, S. (2013). Microsyntactic Variation, in M. den Dikken (ed.), The Cambridge Handbook of Generative Syntax, Cambridge: Cambridge University Press, 899-926. Dahl, Ö & V. Velupillai (2013). The Perfect, in: Dryer, M.S. & Haspelmath, M. (eds.), The World Atlas of Language Structures Online, Leipzig: Max Planck Institute for Evolutionary Anthropology. (Available online at http://wals.info/chapter/68, Accessed on 4-4-2016) Dahl, Ö. (2015). The perfect map: investigating the cross-linguistic distribution of TAME categories in a parallel corpus, in: Szmrecsanyi, Benedikt & Bernhard Wälchli (eds.). Aggregating Dialectology, Typology, and Register Analysis: Linguistic Variation in Text and Speech, Berlin: de Gruyter, 268-290. Ciardelli, I., J. Groenendijk & F. Roelofsen (2009). Inquisitive Semantics: a new notion of meaning. Language & Linguistics Compass 7, 459-476. Grisot, Cristina & Thomas Meyer (2014). Cross-linguistic annotation of narrativity for English/French verb tense disambiguation, Proc. of 9th Conf on Language Resources and Evaluation, Reykjavik, Iceland. Im, Seohyun & James Pustejovsky (2010). Annotating lexically entailed subevents for textual inference tasks, in: Proc. of the 23rd Intern. Florida Artificial Intelligence Research Society conference (FLAIRS 2010). Kamp, H. & A. Rossdeutscher (2013). Perfects as feature shifting operators, ms. Stuttgart. Klis, M. van der, Le Bruyn B. & H. de Swart (2015). Extracting present perfects from a multilingual corpus, paper presented at CLIN26, Amsterdam, The Netherlands, December 18, 2015. Koeneman, O. N. C. J. Lekakou, M. & Barbiers, S. (2011). Perfect Doubling. Linguistic Variation 11, 35-75. Le Bruyn, B., de Swart, H. & J. Zwarts (to appear). From HAVE to HAVE-verbs: relations and incorporation [accepted for publication in Lingua]. Lindstedt, J. (2000). The perfect – aspectual, temporal and evidential, in: Ö Dahl (ed.). Tense and Aspect in the languages of Europe, Berlin: De Gruyter, 365-383. Loáiciga, Sharid, Thomas Meyer & Andrei Popescu-Belis (2014). English-French Verb Phrase Alignment in Europarl for Tense Translation Modeling, in: Proc. of 9th Language Resources and Evaluation Conference, Reykjavik, Iceland. Neijt, A. et al. (2016). Manifest Nederlands op School. Meesterschapsteams Nederlands. (Available online at https://vakdidactiekgw.nl/manifest-nederlands-op-school/, Accessed on 4-4-2016). Nishiyama, A. & J.-P. Koenig (2010). What is a perfect state? Language 86, 611-646. Partee, Barbara (1984). Nominal and temporal anaphora, Linguistics and Philosophy 7, 243-286. Portner, P. (2003). The (temporal) semantics and (modal) pragmatics of the perfect. Linguistics and Philosophy, 26, 459-510. Ritz, M.-E. & D. Engel (2008). Vivid narrative use and the present perfect in spoken Australian English, Linguistics 46, 131-160. Ritz, M.-E. (2012). Perfect tense and aspect. In Binnick (ed.). The Oxford Handbook of Tense and Aspect, Oxford: Oxford University Press. Schaden, G. (2009). Present perfects compete, Linguistics and Philosophy 32, 115-141. Schnabel, P. et al. (2016). Ons onderwijs2032. Eindadvies. Platform Onderwijs2032. (Available online at http://onsonderwijs2032.nl/advies/, Accessed on 4-4-2016) Swart, H. de (2007). A cross-linguistic discourse analysis of the perfect. Journal of Pragmatics 39, 2273-2307. Wälchli, B. & M. Cysouw (2012). Lexical typology through similarity semantics: Toward a semantic map of motion verbs. Linguistics 50. 671–710. Zarcone, Alessandra & Allessandro Lenci (2008). Computational models of event type classification in context. In Proc. of the 6th International Language Resources and Evaluation Conf. (LREC08), Marrakech.