Nederlandse samenvatting
Tijd in Vertaling: de betekenis van de Perfect
1. Vertaalcorpora voor de betekenis van de Perfect
De studie van de betekenis van de Perfect in de West-Europese talen is verzand in taalspecifieke theorievorming, waarbij steeds met dezelfde bril naar dezelfde soort data gekeken wordt. Nieuwe ontdekkingen in dit domein zijn schaars, maar niet omdat we alle gebruiken in kaart hebben gebracht. Zo heeft de literatuur op dit moment bijvoorbeeld geen notie van, laat staan een verklaring voor, het feit dat het Engelse ‘Guys, guys, come and have a look! I found a baby panda!’ in het Nederlands vertaald wordt met de voltooid tegenwoordige tijd (de Perfect) ‘heb gevonden’ en niet met de onvoltooid verleden tijd (de Past) ‘vond’.
Digitale data in de vorm van vertaalcorpora maken hier het verschil: door intelligente corpustechnieken in te zetten kunnen we op een systematische manier op zoek gaan naar variatie die ons toegang verschaft tot de betekenis van de Perfect. Zo kunnen we de digitale revolutie in de Geesteswetenschappen en in verschillende takken van de taalkunde doorzetten in de theoretische taalkunde. De inzichten komen van pas in educatieve conteksten (taalonderwijs), de vertaalpraktijk (vertaalstudenten en professionele vertalers), de computationele taalkunde (ontwikkeling van vertaal plugins, discourse annotatie methoden) en op termijn ook in tweede taalverwervingsonderzoek.
2. Variatie als toegang tot de Perfect
De Perfect staat bekend als variabel (Lindstedt 2000). Wij volgen Schaden (2009) in de aanname dat deze variabiliteit correleert met het feit dat het gebruik van de Perfect wordt ingeperkt door andere werkwoordstijden met (deels) vergelijkbare betekenissen. (1) laat bijvoorbeeld zien hoe de Engelse Perfect zich anders verhoudt tot de Simple Present dan de Nederlandse Perfect tot de OTT.
(1) [context: John is 5 jaar geleden naar London verhuisd en woont daar nog]
a. John [has lived/??lives] in London for 5 years.
b. John [woont 5 jaar in London/??heeft 5 jaar in London gewoond].
Figuur 1 visualiseert Schadens inzicht: door de betekenis van de Perfect te bestuderen in verschillende talen krijgen we steeds een nieuw deeltje van zijn betekenis te zien. Wij kijken naar vijf talen waarvan we weten dat ze hun systeem van werkwoordstijden net iets anders inrichten: Nederlands, Frans, Duits, Engels en Spaans.
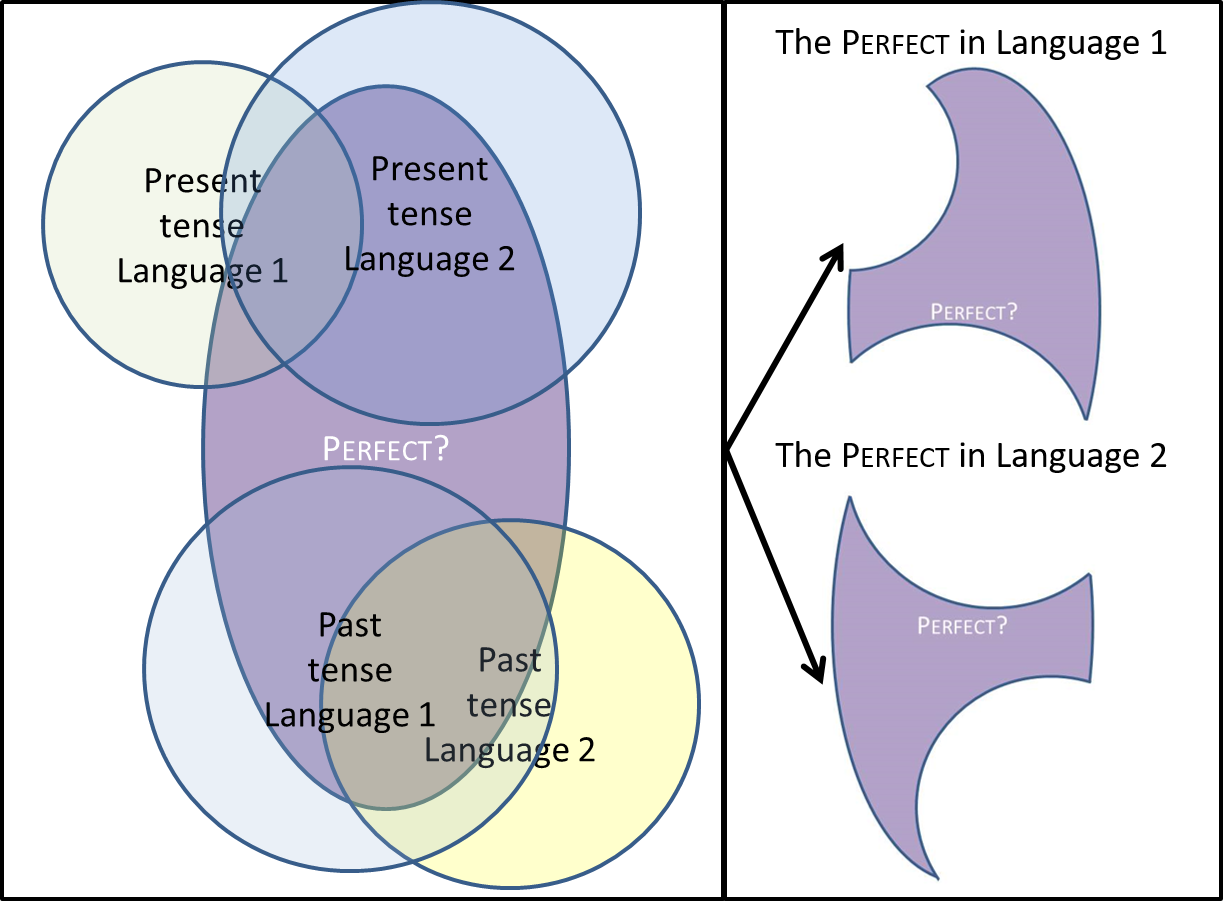
Figuur 1
3. Translation Mining met genre tracking
Het basisprincipe achter Translation Mining is dat variatie in vorm wijst op variatie in betekenis: als je in het Frans in één context prêter gebruikt en in een andere emprunter dan dekken die contexten n.a.w. een net iets andere betekenislading. Dit principe kan ook toegepast worden om verschillende gebruiken van eenzelfde vorm te ontdekken: als in het Nederlands lenen gebruikt wordt in twee contexten waar het Frans in de ene kiest voor prêter en in de andere voor emprunter dan hebben we reden om aan te nemen dat lenen twee gebruiken heeft.
Wij schalen dit principe op en werken met grote multilinguale tekstbestanden (i.e. vertaalcorpora). Over verschillende genres heen (zakelijke teksten, formele dialogen, informele dialogen), selecteren we random 5000 contexten waarin minstens één van de talen een Perfect gebruikt. Met deze selectie kunnen we verschillende gebruiken van de Perfect ontdekken en per taal nagaan hoe de Perfect zich verhoudt tot andere werkwoordstijden. Door statistische analyse kunnen we de verschillende contexten tweedimensionaal weergeven, waarbij elk punt staat voor een specifieke context en de afstand tussen twee punten wordt bepaald door de variatie in vorm over de talen heen. Clusters corresponderen dan met (abstracte) gebruiken:
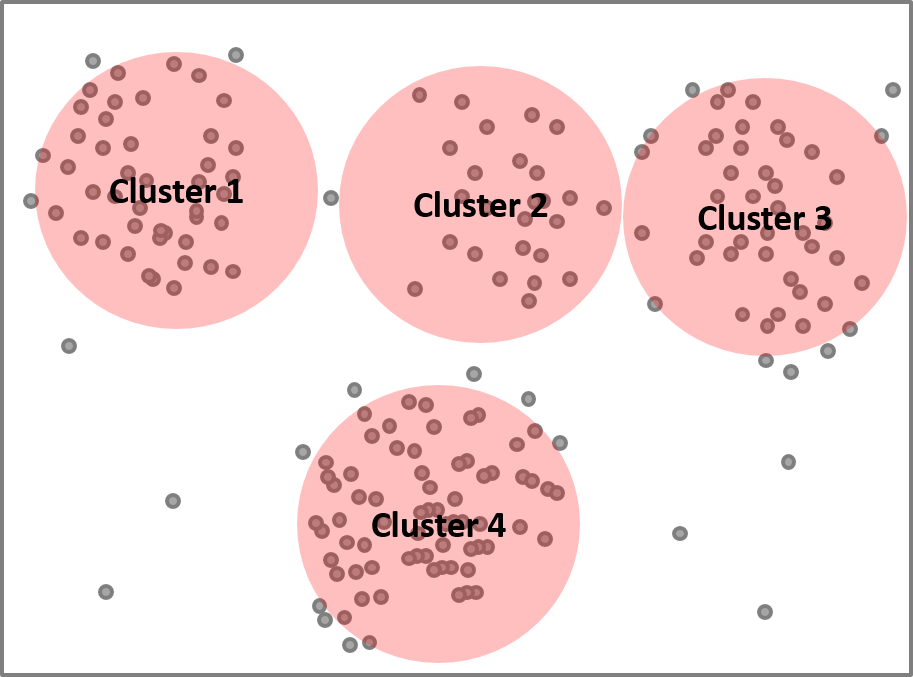
Figuur 2
Voorts kunnen we ook de verschillende werkwoordstijden per taal afbeelden en op éénvoudige wijze tijdssystemen met elkaar vergelijken:
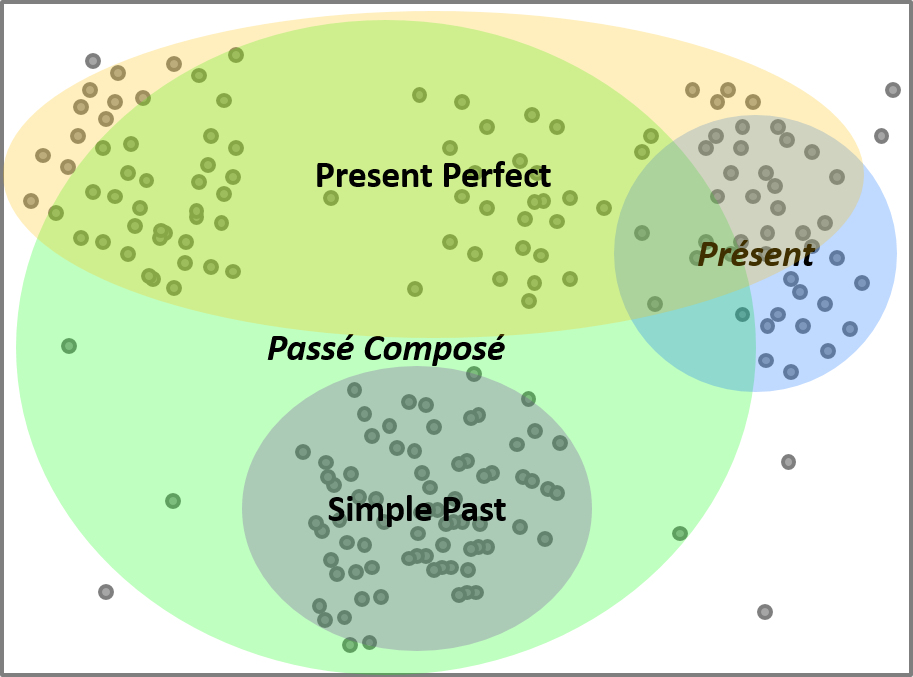
Figuur 3
Tot slot kunnen we de contextclusteringen over genres heen bekijken. Dit laat ons toe om gebruiken die typisch zijn voor dialogen (afwezig in zakelijke teksten) te onderscheiden van gebruiken die vooral op zinsniveau spelen.
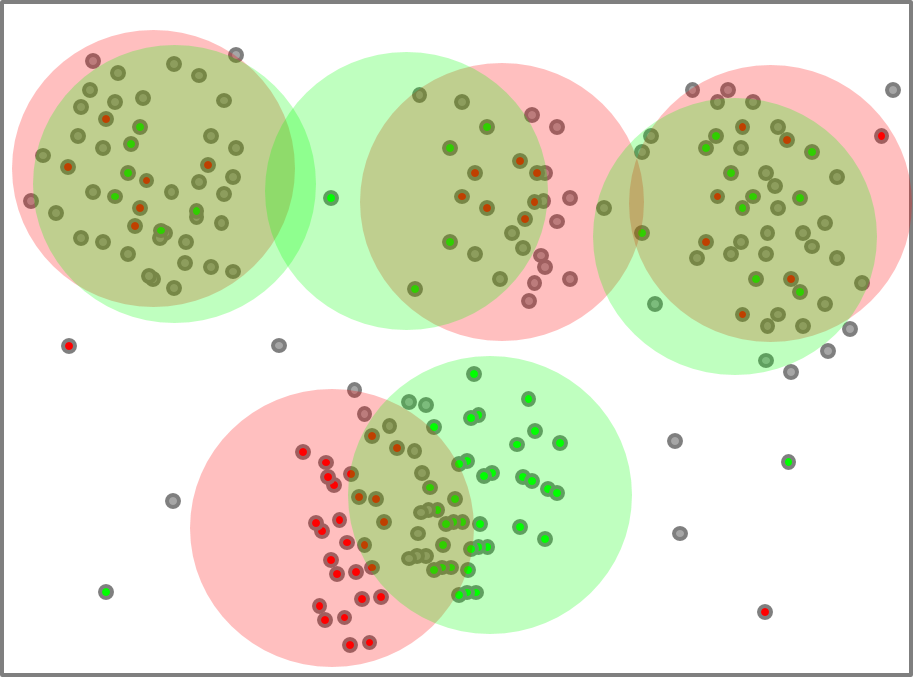
Figuur 4
4. Van data tot theorie en voorspelling
Vooronderzoek laat zien dat we nieuwe en theoretisch relevante data krijgen via Translation Mining. In het bijzonder laat het ons toe om de focus die tot nu toe op de analyse van de Perfect op zinsniveau heeft gelegen te verbreden naar het dialoogniveau. Het project heeft als hoofddoel de systematiek achter de variatie in kaart te brengen zodat we een volledig beeld krijgen van de betekenis van de Perfect in zinnen, teksten en dialogen. In dit project integreren we dus kwantitatief en kwalitatief onderzoek in een cyclus die loopt van inductie over theorievorming tot verificatie/falsificatie. We beargumenteren dat kwantitatief onderzoek op een slimme wijze kan en moet ingezet worden in domeinen van de taalwetenschap die tot nu toe vooral kwalitatief bestudeerd zijn.
5. Kennisbenutting
Naast de taalwetenschap en de contrastieve taalkunde is dit project ook van belang voor de vertaalwetenschap, met name voor de vergelijkende studie van vertalingen van eenzelfde tekst. Om de taalkundige inzichten rond variatie in betekenis te ontsluiten voor vertalers ontwikkelen we een online lesmodule over Tijd in Vertaling. Daarnaast gebruiken we onze datasets om opdrachten voor scholieren te ontwikkelen waarin onderzoekend leren centraal staat, en ontwikkelen we een plugin (MIT-licentie) die geïntegreerd kan worden in bestaande software voor vertalers. Alle ontwikkelde software wordt beschikbaar gemaakt via de website (open source), en kan door computationeel taalkundigen worden gebruikt om tekstannotatie algoritmen te maken voor discourse analyse en machinevertaling.
Om ons onderzoek zo goed mogelijk af te stemmen met mogelijke gebruikers staan wij open voor samenwerking met vertalers en onderwijsprofessionals. Wij werken nu al samen met Renate van der Laan van Taalrijk.